1. 참고 자료
1.1 링크
1.1.1 논문
https://arxiv.org/abs/2507.12846
Enter the Mind Palace: Reasoning and Planning for Long-term Active Embodied Question Answering
As robots become increasingly capable of operating over extended periods -- spanning days, weeks, and even months -- they are expected to accumulate knowledge of their environments and leverage this experience to assist humans more effectively. This paper
arxiv.org
1.1.2 github
1.1.3 github.io
https://mind-palace-laeqa.github.io/
Enter the Mind Palace: Reasoning and Planning for Long-term Active Embodied Question Answering
As robots become increasingly capable of operating over extended periods—spanning days, weeks, and even months—they are expected to accumulate knowledge of their environments and leverage this experience to assist humans more effectively. This paper st
mind-palace-laeqa.github.io
2. 논문 내용 정리
2.1 Figure1 기준 정리

2.1.1 LA-EQA
- traditional EQA settings
- 일반적으로 present environment만을 이해하거나, a single past observation을 recalling 하는 데 초점을 맞춤
- 일반적으로 두 가지 방식으로 구성
- active settings: robots explore the environment from scratch to gather information
- episodic settings: robots answer questions using a single recorded trajectory
- Vision-Language Models(VLM)을 이용한 현재 approches의 한계
- robot의 present observations 또는 a single episodic memory만을 사용
- multiple past experiences 또는 long-term knowledge를 사용하는 것으로 일반화 되지 않음
- LA-EQA (Long-term Active Embodied Question Answering)
- robot이 past experiences를 recall하고 environment를 적극적으로 explore해서 복잡하고 temporally-grounded questions에 답해야 함
- LA-EQA가 traditional EQA settings와 다른점
- agent가 past, present, possible future states에 대해 추론
- 언제 explore할지, 언제 memory를 참조할지, 그리고 언제 observations 수집을 중단하고 final answer를 제공할지 결정
- standard EQA 접근방식은 다음의 한계점 때문에 이 설정에서 동작하기 어려움
- limited context windows
- persistent memory의 부재
- memory recall과 active exploration 결합 불가능
- 기존 EQA approaches를 사용해서 VLM, LLM으로 LA-EQA 수행하는 게 어려운 이유
- representing the robot's past observations accumulated over many deployments across days or months in difficult
- a single run만으로도 다양한 시점에서 수천 개의 이미지가 생성되는데, 대부분의 questions은 몇 개의 관련된 frames만 필요
- retrieving relevant information from long-term memory and exploring places in the environment
- 상당한 combined search space of past and new observations 생성
- uninformed search는 계산 비용이 많이 듦
- 상당한 combined search space of past and new observations 생성
- representing the robot's past observations accumulated over many deployments across days or months in difficult
- 위 문제를 해결하기 위해 robot을 위한 structured memory system 제안
- inspired by the mind palace method from cognitive science
- spatial landmakrs와 memories를 연관시켜 효과적으로 recall할 수 있도록 함
- 논문은 이 방식을 통해 로봇의 long-term observations을 spatial world instances의 series로 구조화
- each instance는 hierarchical scene graph로 표현: semantic observations을 spatially group화 한 것
- spatiotemporal structure는 multiple episodic world instances를 시간에 따라 연결해서 포착
- spatial proximity 및 temporal context에 기반한 relevant experiences의 retrieval을 사용해서 reasoning 및 exploration을 가능하게 함
- episodic experiences를 scene-graph-based world instances로 enbodes
- targeted memory retrieval과 guided navigation을 가능하게 하는 reasoning 및 planning algorithm 형성
- inspired by the mind palace method from cognitive science
OpenAlex
openalex.org
2.1.2 Problem Formulation of Long-term Active EQA
- LA-EQA는 agent가 environment를 능동적으로 exploring하고 long-term memory에서 relevant information을 retrieving해서 environment에 대한 questions에 답하는 setting
- LA-EQA task 정의
- tuple (Q, M, E, x_0, A*)
- Q: question
- M = [m_1, ..., m_N]: list of episodic memories
- E: current environment
- x_0: initial robot pose
- A*: ground truth answer
- environment is dynamic
- visual appearance 및 object states는 시간이 흐름에 따라 변화
- each episodic memory m_i은 L개의 tuple(past robot pose & image observation) 포함
- m_i = [m_i,1, ..., m_i,L]
- m_i,j = (x_i,j, o_i,j): tuple(pase robot pose & image observation)
- specific macro-temporal interval (ex: hour) 동안 수집
- m_i = [m_i,1, ..., m_i,L]
- tuple (Q, M, E, x_0, A*)
- agent는 policy π(ak | xk, hk, Q)를 따른다
- time step k에서 agent state x_k, working memory h_k(Q를 받은 후 history of action and observation), question을 three possible actions 중 하나로 매핑
- retrieve: a pase memory m_i,j를 h_k로 recalls
- explore: robot을 E내의 viewpoint w_i로 이동시키고 new observation o_k를 h_k에 저장
- answer: h를 기반으로 natural language answer A 생성하고 task 종료
- time step k에서 agent state x_k, working memory h_k(Q를 받은 후 history of action and observation), question을 three possible actions 중 하나로 매핑

2.2 Figure2 기준 정리
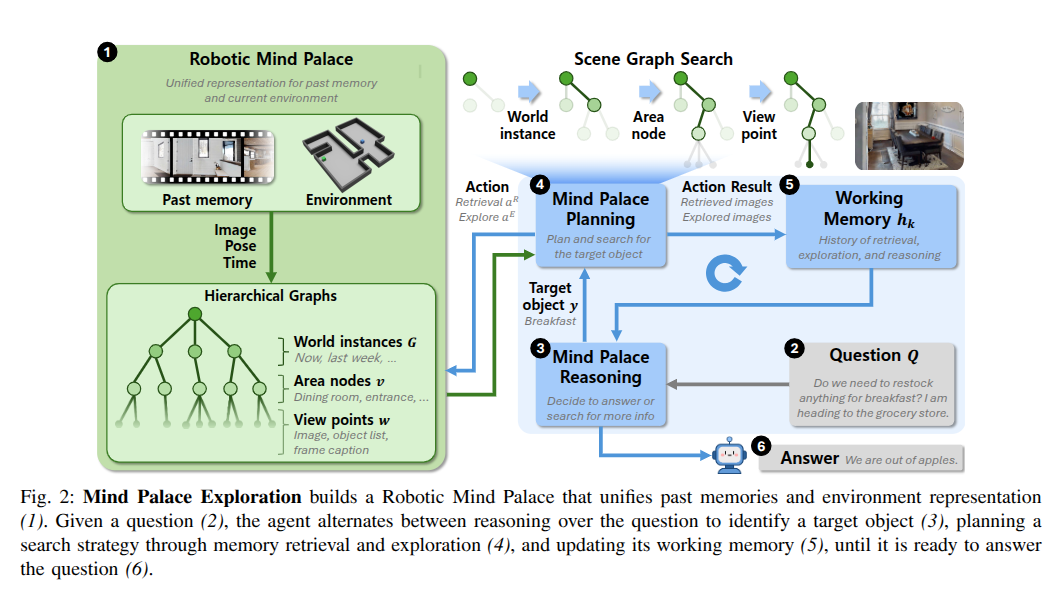
2.2.1 overview
- mind palace technique
- structured spatial memory를 구성해서 complex inforation을 기억
- efficient retrieval 및 relevant memories의 traceable recall 을 가능하게 함
- 이 technique을 long-term memory representation 및 reasoning in robots에 적용할 방안 탐구
- approach consists of three key ideas
- EQA task가 시작되기 전에 long-term memory representation(Robotic Mind Palace M) 구성
- robot의 observations history를 scene graphs의 multiple world instances M = [G0, G1, · · · , GN ]로 요약해서 구성
- LA-EQA scenario 동안 에이전트는 policy π를 사용하여 question Q에 답하기 이해 M내의 world instances에 대해 reasons 및 explores
- value of information 개념을 이용한 early stopping criteria 도입
- next exporation action aE를 개선할 가능성이 낮은 memory retrieving을 피하기 위함
- EQA task가 시작되기 전에 long-term memory representation(Robotic Mind Palace M) 구성
2.2.2 Mind Palace Generation
- Mind Palace는 episodic world instances의 series
- robot image observation 및 trajectories M에 대한 long-term history를 episodes m으로 나눔
- macro-temporal term 기반으로 나눔 (ex: hours, times of day, weeks)
- chunking of the episodes는 자연스럽게 발생
- mobile robot이 continuous operations 중에 battery를 충전하는 동안 모든 activities를 일시 중지해야 함
- each episode는 Mind Palace의 a world instance가 됨
- texts에서 macro-temporal label로 indexing되어 LLM-based agent가 relevant episodes를 선택해서 recall
- robot image observation 및 trajectories M에 대한 long-term history를 episodes m으로 나눔
- An Episodic world instance는 a hierarchical scene graph로 표현
- episode m_i 내의 robot observation 및 trajectory의 sequence가 주어졌을 때, hierarchical scene graph G_i = (V_i, E_i)로 a world representation 구축
- V_i: nodes set
- E_i: edges set (connecting the nodes)
- 구축 방법
- past trajectry에서 dense viewpoints w sampling -> viewpoint nodes set 형성
- each viewpoint node w_i는 다음과 associated
- robot pose x
- images
- a list of detected objects in the image
- frame captions
- list of objects 및 frame captions은 LLM-based agents의 image retrieval selection을 위한 index로 사용됨
- each viewpoint node w_i는 다음과 associated
- viewpoint nodes w는 area nodes v ∈ Vi 로 클러스터링됨
- spatial 및 contextual similarity 기반
- each area node v는 all the clustered viewpoints의 중심점(centroid) 및 object list와 associated
- neighboring viewpoints w와 areas v는 graph edges로 connected
- every w is connected to a v
- forming a hierarchical scene graph represesntation G for each world instance
- Robotic Mind Palace 구성
- a series of world instances representing the past long-term memory [G_1, · · · , G_N ]
- present knowledge of the environment G_0
- LA-EQA task 시작 시, 로봇이 아직 present environment를 탐색하지 않았다고 가정하기 때문에, world instance G_0는 area nodes v로만 초기화됨
- environment의 state 및 object placement가 last mapping in G1 이후 변경되었을 수 있기 때문
- 로봇이 environment를 탐색함에따라 G_0 업데이트
- past trajectry에서 dense viewpoints w sampling -> viewpoint nodes set 형성
- episode m_i 내의 robot observation 및 trajectory의 sequence가 주어졌을 때, hierarchical scene graph G_i = (V_i, E_i)로 a world representation 구축

2.2.3 Mind Palace Reasoning and Planning
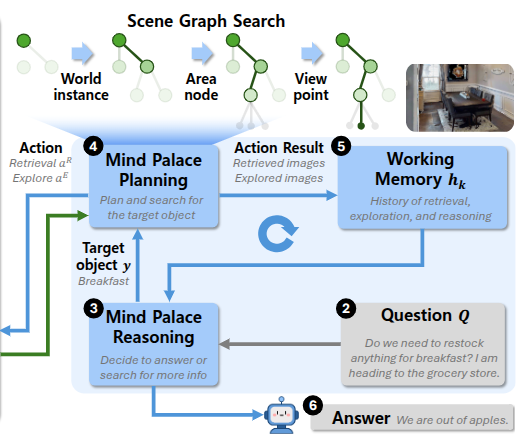
- LA-EQA task를 위해 robotic mind palace에 대해 reasoning 및 planning 수행
- three interleaving steps (상호작용 스텝)
- reasoning: question 기반으로 어떤 오브젝트 또는 spatial concept y를 search해야 하는지, 언제 agent가 question에 답할 수 있는지 결정
- planning: information 수집을 위해 Mind Palace에 대한 hierarchical planning
- updating: information로 working memory h 업데이트
- three interleaving steps (상호작용 스텝)
- Reasoning over the LA-EQA
- reasoning의 첫 번째 단계는 robot이 working memory h_k를 사용해서 question Q에 답할 수 있는 suficient information을 가지고 있는지 여부 결정
- agent는 h_k와 Q를 가지고 VLM 쿼리
- VLM이 question에 답하는 것이 가능하다고 응답하는 경우
- 에이전트는 answer action을 실행하고 VLM query로 answer A 제공
- VLM이 question에 답하는 것이 불가능하다고 응답하는 경우
- 에이전트는 LLM에게 a target object 또는 a spatial concept y를 식별하라고 쿼리
- 식별 대상: 명시적으로 question에 언급된 a specific object 또는 an inferred cue(ex: something to make a coffee)
- 이는 exploration을 위한 next object goal이 됨
- 에이전트는 LLM에게 a target object 또는 a spatial concept y를 식별하라고 쿼리
- VLM이 question에 답하는 것이 가능하다고 응답하는 경우
- Planning over episodic world instances G in the Mind Palace
- Mind Palace planning은 y를 효율적으로 찾기 위한 world instances G의 sequence를 selecting하는 것으로 시작
- two-step reasoning process로 LLM 쿼리
- question에 답하는 데 multiple world instances에 걸친 object search가 필요한지, 아니면 only a specific instance만 관련된 것인지 추론하도록 asks
- 위 reasoning에 기반해서, LLM은 subset of G ∈ M를 선택하고 G의 sequence를 계획
- heuristic으로 sequential planning을 guide
- present instance G_0보다 past world instances를 우선시하도록 guide
- 과거의 위치에 대한 사전 지식을 활용하는 것이 현재 상황에서 오브젝트를 탐색하는 효율성을 높여줄 수 있기 때문
- heuristic으로 sequential planning을 guide
- Planning over areas v in the scene graph
- a world instance G_i가 주어졌을 때, y를 찾을 확률을 최대화하는 탐색할 areas v의 sequence 계획
- 이는 object-goal navigation problem으로 framed됨
- 방법론
- LLM한테 each area v ∈ Gi에서 object y를 찾을 확률을 출력하도록 쿼리
- forward search planner 사용: y를 찾기 위한 cost J를 최소화하는 areas v의 best sequence를 찾음
- present scene graph G_0을 탐색할 때, cost는 로봇의 current pose x_k와 each area의 centroid 사이의 path length로 정의
- 대조적으로, past graphs에 대해 추론할 때, agent는 travel distance에 상관없이 constant cost로 어떤 area든 teleport 가능
- a world instance G_i가 주어졌을 때, y를 찾을 확률을 최대화하는 탐색할 areas v의 sequence 계획
- Exploring viewpoint w and replanning
- search할 area v_i가 주어졌을 때, G_i 속 textual information을 기반으로 viewpoints w를 select하도록 LLM 쿼리
- object y는 frame captions 또는 object list에 나타날 수 있지만 종종 언급되지 않는 경우가 있음
- textual information를 고려해서 relevant viewpoitns 추론
- 로봇은 Mind Palace에서 images를 recalling 하거나 robot-specific motion planner를 사용해서 environment 속 viewpoints로 navigating 해서 images taking
- retrieved 또는 observed images는 working memory h_k에 저장
- object y가 VLM에 의해 images에서 detecting 되거나 exploration limits에 도달할 때까지 areas v와 viewpoint w에 대한 planning 반복
- object가 detecting 되면 remaining world instances G에서 y를 search하고 LA-EQA에 대한 reasoning step으로 이동
- search할 area v_i가 주어졌을 때, G_i 속 textual information을 기반으로 viewpoints w를 select하도록 LLM 쿼리
2.2.4 Early Stopping of Memory Retrieval for Navigation
- unlimited memory retrieval case와 비교할 만한 exploration efficiency를 유지하면서 memory retrieval을 줄이는 방법 고안
- stopping criteria: past memory retrieval을 중단하고 exploration을 진행할 시점 결정
- present instance G_0을 포함하는 world instances의 sequence가 주어졌을 때,
- threshold P(y) >= 1-q 이상의 확률로 object y가 위치할 수 있는 areas v ∈ G0의 prediction set을 형성하기 위해 LLM 사용
- prediction set을 사용해서, past world instances [G_1, G_2]에서 memory retrieval을 즉시 중단하기 위한 두가지 조건 정의
- the prediction set contains only on area
- further memory retrieval이 prediction set에서 탐색할 next sequence v_i에 대한 robot plan을 개선하지 못하는 경우
- past memory retrieving에서 얻는 expected utility gain을 정량화하고, expected exploration cost J를 줄이는 Value of Information (VoI)의 개념을 사용해서 sequence에 대한 possible improvements 평가
2.3 Figure3 기준 정리

2.3.1 Long-term Active EQA Benchmark
- 기존 EQA datasets은 short time spans (i.e, the same day)에 걸친 scene understanding에 초점을 맞춰 scene의 long-term evolution을 capture하는 능력 부족
- 위를 해결하기 위해 구축한 데이터셋이 Long-term Active EQA Benchmark
- 3 simulated and 2 real-world scenes로 구성
- for each simulation scene
- 일반적인 일상 루틴으로 인한 변화를 반영하여 여러 날에 걸쳐 5-10 scene variations 생성
- for real-world scene
- 6개월 동안 industrial site와 office environment에서 11개의 trajectories 수집
- 1 trajectory: 30~60분
- 6개월 동안 industrial site와 office environment에서 11개의 trajectories 수집
- for each simulation scene
- 3 simulated and 2 real-world scenes로 구성
- Question Types
- Past questions: a single past trajectory에서 관찰된 a specific event와 관련
- Present questions: only current environment exploration만 필요
- Multi-past questions: multiple past trajectories에서 information을 종합하는 것 필요
- ex) "What do we usually eat for breakfast?"
- Past-present questions: historical memory와 current scene 모두에 대한 reasoning 필요
- ex) "Are we missing anything we usually have for breakfast?"
- Past-present-future questions: past와 present observations 모두에 기반해서 future outcomes 예측 필요
- ex) "When do you think we wll run out of apples for breakfast?"
2.3.2 Question Types example
- Habitat HM3D House 1

- Habitat HM3D House 2

- NVIDIA Isaac Large Warehouse

- Real-world Office Environment

- Real-world High-rise Construction Site

2.6 Figure6 기준 정리

2.6.1 Real-world Hardware Experiments
- lagged-robot을 사용해서 27개의 서로 다른 영역으로 구성된 1,000 m**2 이상의 사무 공간에서 실제 LA-EQA use cases에 대한 Mind Palace Explorationd의 efficacy 시연
- 로봇은 과거 4일간의 office inspecting과 2024년 10월 부터 2025년 3월까지 6개월간 monthly inspections을 포함하여 10개의 past episodes에 접근
- GPT-4o 쿼리를 제외한 모든 Mind Palace memory storage 및 planning은 로봇에서 수행
- user는 컴퓨터로 원격으로 로봇에게 question 전달, 로봇은 task를 완료하면 answer 보고
- questions은 realistic office scenarios 반영해서 LA-EQA의 실용적인 유용성 보여줌
- ex) searching for tools, tracking missing packages, identifying vacant desks unused for days